GPU access¶
Graphics processing units (GPUs) are specialized processors that can dramatically accelerate execution of parallelizable algorithms.
The most common use cases for GPUs in high energy physics are training and inference of machine learning models, however there are other frameworks and algorithms optimized to run on GPUs. For example, Purdue AF also allows you to use GPUs to accelerate RooFit fits.
How to access GPUs at Purdue AF¶
1. Direct connection¶
You can start an AF session with interactive access to an Nvidia A100 GPU by selecting it at the resource selection step (see screenshot below). You will have a choice of either a 5 GB "slice" of an A100, or a full 40 GB A100.
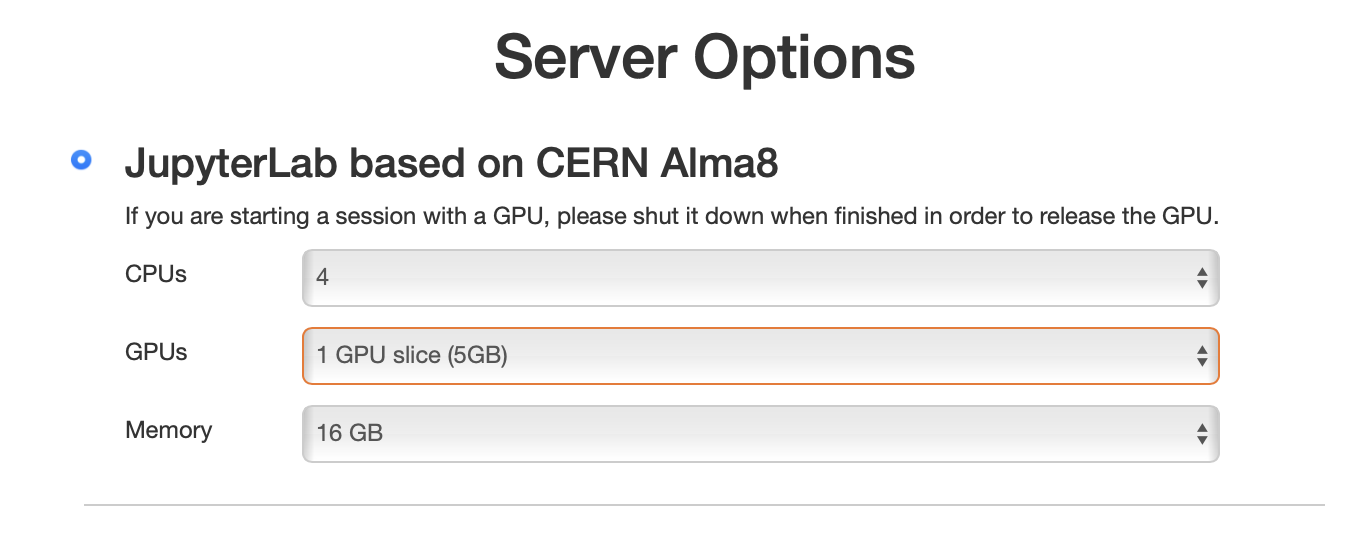
| Configuration | Memory | Number of instances | Availability |
|---|---|---|---|
| 5 GB "slice" of A100 | 5 GB | 14 | Usually immediate |
| Full A100 GPU | 40 GB | 4 | Subject to availability |
Tip
The resource selection form shows the current availability of each GPU configuration next to the corresponding option, so you can see before starting the session whether a full A100 is free.
Note
If you selected a GPU, your session will have CUDA 12.4 and cudnn 8.9.7.29
libraries loaded. Take this into account if you need to install particular
versions of ML libraries such as tensorflow — these libraries are notoriously
sensitive to the CUDA version.
Important
Please terminate your session after using a GPU in order to release it for other users. Full 40 GB A100 instances are in short supply, and sessions holding one are automatically shut down after 24 hours of inactivity (regular sessions are only shut down after 14 days).
2. Slurm jobs (Purdue users only)¶
You can use Slurm to submit multiple GPU jobs to run in parallel. To request a GPU
for a Slurm job, simply add the --gpus-per-node=1 argument to the sbatch command.
- Slurm jobs submitted directly from the Purdue AF interface are executed on the Hammer cluster, which features 22 nodes with Nvidia T4 GPUs.
-
If you need more GPUs, or different GPU models, consider submitting Slurm jobs on the Gilbreth cluster. To log in to Gilbreth directly from the Purdue AF interface, simply run
ssh gilbrethand use BoilerKey two-factor authentication. Once logged in, you can use the Slurm queues on Gilbreth to run GPU jobs.Important
The only storage volume shared between Purdue AF and the Gilbreth cluster is
/depot/— save the outputs of your jobs there.
GPU support in common ML libraries¶
-
PyTorch — does not require any special installation, as long as its version supports
CUDA 12.4andcudnn 8.9.x(this is already true for the global Pixi environment). See the PyTorch CUDA semantics documentation. -
TensorFlow:
- Install
tensorflow[and-cuda]usingpip(already done in the global Pixi environment). - Learn how to use TensorFlow with GPUs: TensorFlow GPU guide.
- Install
-
XGBoost — enable GPU support by setting the
deviceparameter tocuda. Refer to the XGBoost GPU documentation for details.
You can verify that your session sees the GPU with nvidia-smi, or from Python:
If you experience any issues, or are missing any ML libraries, please contact Purdue AF support.